Examining the scheduling (optimization) problem at a high level means asking the question, ”How can the problem be divided into logical data areas?”
The illustration below divides the problem into several logical areas.
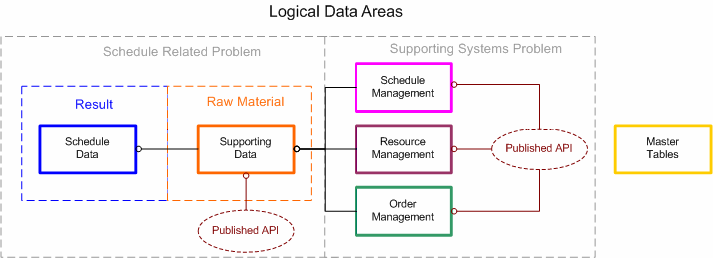
Figure 1: Logical Data Areas
It first separates the Schedule-related problem data from the supporting external system data identified by the large dashed boxes below.
Within the Schedule-related problem, the data are further separated into two additional areas called the result (Schedule data), and the raw material (supporting data).
The supporting system data are also divided into three additional areas: Schedule, Resource, and Order Management. The following sections look at each data area in more detail.
The Schedule area represents a group of data (tables) that holds all of the Schedule-specific data attributes. The key aspect here is that multiple Schedules are supported for different Schedule types, from reservations to real-time dispatch Schedules. The flexibility exists to have only one Schedule (as with previous Descartes Route Planner (LNOS Fleetwise) versions), or to have as many different Schedules as each implementation requires.
A Schedule data set represents the result for a given optimization problem. Going forward, the Schedule data set tables will be the focal point for all optimization information (Schedule and all associated Bucket, Route, and Stop information needed to import and export all Schedule details).
The supporting data area represents a group of data tables providing the data needed to select and solve a specific scheduling problem. Think of the supporting data as the raw material of what needs to be done. It supplies the how, the who, and the what, that needs to be done. Different supporting data combinations represent different possible scheduling problems.
At a minimum, the Schedule data and supporting data areas provide enough data points to create and customize different Schedule possibilities. Think of the Schedule data as the result for a possible solution to a specific scheduling problem, just as a cake is the result of a specific recipe. Think of the supporting data as the raw material needed to create the cake: flour, eggs, oven, and a baker to bake the cake. Now think of the baking activity in virtual space where several baking scenarios can be performed using the same raw materials in different amounts and combinations to produce different cakes. The same can be done with different supporting data to produce different Schedules.
Q. Why separate and divide the two?
Q. Why not just feed the data from the external or supporting systems straight into a specific Schedule?
The reason is that a separate supporting data area provides a buffer that can be incorporated with new data coming from the external systems. This provides the flexibility to integrate with most generic order or resource management systems without having them provide all specific data attributes needed by the scheduling technology. This also allows Descartes Route Planner to remove and summarize data attributes at the Schedule level so the optimizer does not need to deal with unnecessary data attributes and table joins.
Example: the current order line details (such as individual measure amounts) can be summarized into one amount at the supporting data level. In addition, the supporting data area provides the capability for any Schedule to be reset to its default state.
Ü Note - The raw material (supporting data) can be supplied via external sources such as a published API, Business Documents, or managed from within one of the Descartes Route Planner application components. The supporting systems represent some of the other Descartes Route Planner application components needed to round out the whole scheduling solution.
The current solution includes the following supporting systems:
· Order Element Management
· Resource Element Management
· Schedule Element Management
· Master Tables
![]()